互联网网站在初期用户量和访问量一般都很小,往往只需要采用最简单的技术架构就能对外提供稳定服务。最简单的架构通常采用的是单机应用服务器、单机数据库服务器这样的单体架构。成功的互联网网站,比如电商平台,流量、用户量、交易量等核心指标是呈指数增长的,所以就需要提升网站系统的性能,来应对更大的负载。通过向系统中增加资源来提升系统性能的能力,被称为可伸缩性(scalability)。为了提升系统的可伸缩性,典型的大型网站,比如 eBay、Amazon 和淘宝等,几乎都经历过从单体架构向分布式架构演进的过程。本文主要关注大型网站或 Web 服务这类系统,解释系统的性能和可伸缩性相关的核心概念,并介绍系统的性能指标、系统的扩展策略和分布式架构风格,同时也总结分析典型大型网站的可扩展性架构演进案例,案例包括 eBay、Amazon、淘宝等。
术语与概念
让我们先看下,系统的性能和可伸缩性的相关的概念[1]:
- 性能(performance),是系统在指定时间和使用资源的条件下所完成工作量。度量性能的最重要指标是,吞吐量和响应时间。
- 吞吐量(throughput),是在单位时间内系统能够处理的工作负载(workload)的量。对于文件 I/O 来说,吞吐量可以用每秒字节量来表示。对于企业应用来说,吞吐量通常用每秒事务数(TPS)来度量。
- 响应时间(response time),是一次操作完成的时间,包括用于等待服务的时间(wait time)和服务时间(service time),也包括用来传送结果的时间(transmission time)。
- 延时(latency):是描述操作里用来等待服务的时间(wait time)。在某些情况下,它可以指的是整个操作时间,等同于响应时间。
- 系统的容量(capacity),是指最大有效负载或吞吐量的指标。它可以是一个绝对最大值或性能衰减至低于一个可接受的阈值之前的临界点。
- 瓶颈(bottleneck):在系统性能里,瓶颈指的是限制系统性能的那个资源。分辨和移除系统瓶颈是系统性能的一项重要工作。
- 工作负载(workload):系统的输入或者是对系统所施加的负载叫做工作负载。比如,对于数据库来说,工作负载就是客户端发出的数据库请求量。
- 可伸缩性(scalability),是指通过向系统中增加资源来应对增长的工作负载的能力。
系统的可伸缩性与性能紧密相关,性能关注的是系统执行当前工作负载有多快,而可伸缩性关注的是当负载增长或者资源增加时系统性能会如何变化。也就是说,可伸缩性关注的是性能变化曲线,曲线是在给定资源的条件下的负载-性能曲线和在给定负载条件下的资源-性能曲线,而性能只是曲线上的一个点。
可伸缩性通常要考虑的问题是,“如何应对工作负载的增长,有哪些措施”,“如何向系统增加资源来处理额外的工作负载”[2]。
严格意义上,术语“scalability”同时包含伸和缩两方面能力[3][4],即同时包含增强系统处理能力和缩减系统处理能力。当术语“scalability”同时表示伸和缩时,翻译为“可伸缩性”更准确。不过很多英文资料[1:1][2:1][5][6][7][8]在使用术语“scalability”时,所指的含义只是增强系统处理能力,而不考虑缩减系统处理能力,所以很多中文资料会把“scalability”翻译为“可扩展性”。另外,“large-scale”通常会被翻译为“规模化”、“大规模”或“大型”。类似的,“large-scale distributed system”通常被翻译为“大规模分布式系统”或“大型分布式系统”。
术语“scalability”会被翻译为“可扩展性”,而术语“extensibility”在很多中文资料中也会被翻译为“可扩展性”,容易混淆,需要注意区分。“extensibility”指的是系统增加新的功能以及修改现有功能的能力。可扩展性的实现模式有很多[9],典型的是插件(plugin),比如浏览器、编辑器、IDE 等的“扩展”(extension),或直接称为“插件”(plugin)。插件与核心应用程序分开开发,运行时动态加载,使第三方开发人员能够扩展应用程序。除了插件模式外,拦截过滤器(Intercepting Filter)设计模式,也是实现可扩展性的经典模式,通过过滤器对某逻辑做扩展。“maintainability”(可维护性)是相对“extensibility”含义更广的特性。可维护性是指系统可被修改(modification)的难易程度,修改包括纠正(correction)、改进(improvement)和适应(adaption)。可维护性中的改进性的修改,可以认为等同于“extensibility”。
性能、可伸缩性等特性都属于系统的架构特性(architecture characteristics)[7:1],这些特性实现的是系统的非功能性需求,是影响系统是否成功的至关重要的关注点。除了被命名为架构特性外,很多时候也被统称为系统的质量属性(quality attributes)。
性能指标
吞吐量和响应时间是度量性能的最重要指标,两者之间有着非常复杂的关系[10]。假设某系统吞吐量是每秒执行 1000 个任务,不能简单的认为每个任务的平均响应时间为 1 ms。假设处理此吞吐量的系统有 1000 个并行、独立、同构的服务通道,在这种情况下,每个请求可能正好消耗 1 秒。所以,不能从吞吐量推算出响应时间,必须单独测量。假设在单 CPU 计算机上执行某任务耗时 1 ms,如果任务请求被很好地串行化,那么理想情况是在 1 秒的时间内能执行该任务 1000 次,吞吐量是每秒执行 1000 个任务。但实际情况这些任务很可能是随机请求的,CPU 调度程序和任务对共享资源的竞争可能会将吞吐量限制在远低于每秒 1000 个任务的数量。所以,也不能从响应时间推算出吞吐量,必须单独测量。总体来说,任务的响应时间越短,系统所能达到的吞吐量就越高。
统计服务的响应时间,常见的使用平均响应时间。平均响应时间,计算的是多次请求的响应时间的算术平均值。不过平均响应时间并不是很合适的统计值,百分位数(percentile)能更好反应人类的延迟体验。假设响应时间的第 90 百分位数(90th percentile)的值是 100 ms,意味着 90% 请求的响应时间小于 100 ms,10% 请求的响应时间大于 100 ms。常见百分位数有第 50、90、95、99 和 99.9 百分位数,分布缩写为 P50、P90、P95、P99 和 P99.9,其中第 50 百分位数叫做中位数(median)。百分位数相对算术平均值的优点是能排除异常值(outlier)。假设有一组共 10 个的响应时间数据分别是(递增排序,单位 ms):[924, 928, 954, 957, 961, 965, 972, 979, 987, 2373]。可以明显看到最后一个值 2373 和其他所有值都有较大差别,这个值是异常值,可能是因为网络异常而引入,需要排除。如果计算这组响应时间数据的算术平均值(平均响应时间 1100 ms),这个异常值会导致统计结果与真实情况偏差。而这组数据计算的 P50 中位数响应时间是 961 ms,P90 响应时间是 987 ms,百分位数能排除异常值,统计值结果更加可信。
资源过载与峰值流量
典型的系统负载增加下的吞吐量变化曲线和响应时间变化曲线[1:2]:


在开始的一段时间内,随着工作负载增加,吞吐量也随着线性增加。但是随着到达某一点,也就是“拐点”(knee),即图中两条曲线的分界点,负载对于资源的争夺开始影响性能,偏离了线性变化,甚至出现吞吐量不增加反而下降的现象。这种现象通常是由于系统中一种或者多种重要资源极度过载(overload)无法有效工作而造成的。一个说明这种现象的例子是多线程执行计算密集型任务,当线程数小于等于 CPU 核数时,通过增加线程数来并发执行更多任务(增加工作负载)吞吐量也会随着线性增长,但是在全部 CPU 核都接近 100% 使用率后,更多的线程会导致更多的线程上下文切换,额外消耗 CPU 资源,结果实际完成的任务数会变少,整体吞吐量反而下降。
响应时间的变化曲线也是类似。如果出现 CPU 过载,会导致响应时间慢速下降。如果出现内存过载,系统利用磁盘换页(或者使用 swap)来补充内存的时候,会导致响应时间快速下降。
工作负载过大导致系统性能出现拐点的情况,显然是需要尽量避免的,应对策略有两种:
- (1) 通过过载保护,避免达到那样的工作负载级别。
- (2) 通过提升系统性能,让系统能有效处理这样的工作负载级别。
第一种策略,在应对超预期的突发流量时比较常见,通过限流、降级等方式避免系统过载。不过这种策略的问题是降低了用户体验。第二种策略,应对的是预期内的正常的负载增长,针对可能的过载资源,通过性能调优或扩展硬件资源解决。
应对瞬间的峰值流量,最有代表性的场景是秒杀抢购。类似的,秒杀抢购系统的设计的两种策略是,排队限流和提升扣减库存性能。通常真实抢购的秒杀系统会结合使用多种策略,但有所侧重。主要策略采用排队限流,典型的案例是小米抢购限流峰值系统[11]。主要策略采用提升扣减库存性能,典型的案例是淘宝秒杀系统。具体实现上,淘宝秒杀系统早期是基于 Redis(Tair)实现扣减库存[12],后来针对扣减库存场景优化数据库内核的性能,直接在数据库上实现扣减库存[13]。
本质上来看,互联网应用的峰值流量的应对策略,与日常生活中的峰值流量的应对策略类似,典型的就是节假日和春运期间的交通系统。临时应对策略无非就是增加购票和安检处理窗口、增加车辆班次、以及增加值班人员让排队更加有序等等,长期对应策略主要就是增强交通基础设施的流量处理能力,包括扩建火车站、修建高铁、修建高速公路等等。
系统扩展策略
垂直伸缩与水平伸缩
扩展系统的硬件资源有两种策略,(1) 垂直伸缩(vertical scaling),也叫做向上伸缩(scaling up); (2) 水平伸缩(horizontal scaling),也叫做向外伸缩(scaling out)。
- 垂直伸缩,意味着向单个服务器添加资源,提高单个服务器节点的性能(吞吐量、响应时间)。
- 水平伸缩,意味着向系统添加更多服务器节点,提高系统的吞吐量。
垂直伸缩,通常是给服务器添加 CPU、内存或存储等,比如更新服务器获得更多处理器或者更多虚拟核,通过增加内存减少 I/O 操作,通过切换到 SSD(固态硬盘)改善 I/O 访问速度,通过升级网络设备提高网络吞吐能力。如果系统急切需要扩展,垂直伸缩可能是最容易的,但是垂直伸缩会随着规模增长而越来越昂贵。另外的问题是垂直伸缩是有极限的。无论你愿意花多少钱,内存都不可能无限地增加下去。类似的限制还有 CPU 的速度,每台服务器的虚拟核数目,硬盘的速度。简单说来,到了某个极限,没有任何硬件能力能够继续增加。
水平扩展不需要购买更加昂贵的硬件设备,而是需要增加额外的相对廉价的服务器节点。水平伸缩总是可以增加更多服务器,而不会像垂直伸缩那样遭遇到单台服务器的极限。但是与垂直伸缩不同,为了让系统架构能支持水平扩展,必须付出相当的开发代价。
总的来说,更多硬件资源意味着更高的吞吐量和更好的响应时间,同时要付出更高的成本。考虑到成本和性能之间的基本关系,通常要用最少量的硬件,让系统满足性能目标。水平伸缩和垂直伸缩的成本对比,如下图所示,X 轴表示系统的计算能力(容量),Y 轴表示单位计算能力(容量)的价格,虚线表示垂直伸缩的成本,实线表示水平伸缩的成本[3:1]。

另外,需要注意的是,向上伸缩(scaling up)的相反方向是向下伸缩(scaling down),向外伸缩(scaling out)的相反方向是向内伸缩(scaling in)。向上伸缩或向外伸缩,增强系统处理能力;向下伸缩或向内伸缩,缩减系统处理能力。需要缩容的场景,比较典型的是为了处理短期大流量的扩容之后的缩容,比如大促,黑色星期五(Black Friday)和双十一等。在大促期间,通常需要增强系统处理能力,即扩容,而在大促结束后,流量回归日常,为了避免资源浪费,需要缩容。
扩展立方体模型
Martin Abbott 曾经在 eBay 工作 6 年(1999 ~ 2005),并担任 CTO 等职位。基于 eBay 架构的扩展的实践经验[14][15],Abbott 在《可扩展的艺术》(The Art of Scalability,2009)书中总结了三个维度的扩展方法,创造出扩展立方体模型(scale cube),如下图所示(图片来源[16])。

扩展立方体模型的三个维度代表的含义分别是:
- X轴扩展:通过克隆或复制扩展,即通过克隆服务或复制数据库以分散负载。
- 克隆服务,在多个服务实例之间实现请求的负载均衡。
- 复制数据库,一种方法是在数据库的前面加缓冲层,减轻数据库的负载。另外的方法是数据库的主从复制,主库可读可写,从库只读,主从读写分离,在多个从库实例之间实现读请求的负载均衡。主从读写分离的问题是无法分散写请求。
- Y轴扩展:通过拆分不同的东西来扩展,即按功能拆分服务和数据库。按功能拆分服务,是 SOA 和微服务架构所推崇的架构风格,这种架构风格推荐的是每个服务都拥有自己的数据库(database per service)。另外,也可以选择不拆分服务,只拆分数据库。
- Z轴扩展:通过拆分类似的东西来扩展。通常是拆分非常大而且类似的数据集,也被称为数据分区(partitioning)或数据分片(sharding)。
Y轴的拆分,也被成为垂直拆分,Z轴的拆分,也被成为水平拆分。容易发现,这三个维度都属于水平伸缩。三个维度的扩展有不同优缺点:
- X 轴扩展的成本最低并且最易于实施。
- Y 轴扩展的成本和实施难度较高,但是相对 X 轴,除了进一步提高系统吞吐量外,额外的好处是有助于系统解耦和故障隔离,并且有助于团队成员的职责拆分和团队规模化。
- Z 轴扩展的成本最高并且实施最困难,但带来最大扩展性。
SOA 与微服务
本质上来看,微服务架构是一种特殊的 SOA 架构,在“微服务”术语诞生之前,亚马逊的 SOA 架构实现被认为是“SOA done right”(正确实现的 SOA)[17]。Netflix 的 SOA 架构实现也在“微服务”术语诞生之前,Netflix 认为自己实现架构的是“fine-grained SOA”(细粒度的 SOA)[18]。James Lewis 和 Martin Fowler 等人是“微服务”概念的早期提倡者,他们将亚马逊和 Netflix 的 SOA 架构实现归类为微服务的经典案例[19]。所以,SOA 和微服务的关系可以简单理解为,微服务是“fine-grained SOA”或“SOA done right”。
根据 Martin Fowler 的解释[19:1][20],SOA 与微服务的关系,如下图所示:

注意,解决网站的可扩展性问题,不一定需要演进为服务化架构。架构服务化意味着将完整的单体服务按业务的功能领域做垂直拆分,而实际上在应用服务层可以通过部署多个相同副本的单体服务的方式实现系统的水平扩展,网站的可扩展性问题主要在数据存储层上。拆分应用服务的好处更多在于能实现组织团队的规模化,拆分后的小团队独立维护各自的微服务,能有效提升研发效率。解决数据库的扩展性的策略有,数据复制(数据缓存、数据库主从读写分离)、数据垂直拆分、数据水平拆分(也叫数据分片,sharding)。数据库被拆分后,如果单个事务内的数据分散在多个节点就要解决分布式事务问题,但是实现分布式事务代价太大,通常的选择是牺牲一致性,仅满足最终一致性(BASE)。对于无或弱事务要求的非关系型的数据,也可以选择存储在可扩展性能力更强的 NoSQL 数据库。
没有拆分应用服务,始终采用单体架构的经典案例是 Instagram,2019 年 Instagram 在技术博客上有这样一段话[21]:
Our server app is a monolith, one big codebase of several million lines and a few thousand Django endpoints, all loaded up and served together. A few services have been split out of the monolith, but we don’t have any plans to aggressively break it up.
Instagram 解决可扩展性问题,主要在数据存储层[22][23]。在 Instagram,PostgreSQL 被用于存储用户信息、媒体元数据、用户关系等数据,照片媒体数据存储在亚马逊 S3 服务上。Instagram 对 PostgreSQL 数据库做了主从读写分离、数据垂直拆分和数据水平分片。另外,Instagram 从 2012 年开始使用 Cassandra 数据库,Cassandra 被用于存储 Feed 流、活动等数据。类似的,Reddit 也是单体架构,在数据存储层做了可扩展性改造[24]。对 PostgreSQL 数据库做了主从读写分离和垂直拆分,拆分为四个主数据库,链接、帐户、子版块、评论、投票和杂项,每个主数据库都从数据库。另外,投票数据存储在 Cassandra 数据库。
自动弹性伸缩
与“可伸缩性”(scalability)类似的特性是“弹性”(elasticity),弹性是按需自动增加或减少资源的能力,可伸缩性和弹性的区别是,可伸缩性的系统不必须具备自动伸缩的能力,而弹性的系统需要具备自动伸缩的能力[4:1][25]。所谓的“按需”,主要就是根据系统负载进行自动伸缩。来看下,微软 Azure 的 AZ-900 培训文档对术语“scalability”和“elasticity”的定义[4:2]:
Scalability: The ability to increase or decrease resources for any given workload. You can add additional resources to service a workload (known as scaling out), or add additional capabilities to manage an increase in demand to the existing resource (known as scaling up). Scalability doesn’t have to be done automatically.
Elasticity: The ability to automatically or dynamically increase or decrease resources as needed. Elastic resources match the current needs, and resources are added or removed automatically to meet future needs when it’s needed (and from the most advantageous geographic location). A distinction between scalability and elasticity is that elasticity is done automatically.
可伸缩性是系统架构层面的能力,而弹性是基础设施层面的能力,弹性伸缩的基础设施,让系统的可伸缩性能力进一步提升。2011 年 9月,NIST 发布文档 SP 800-145 “The NIST Definition of Cloud Computing”,文档给出云计算的定义,该定义是目前最被广泛认同的云计算定义。定义包含云计算模型,模型中描述了云计算的五个基本特性,其中“快速的伸缩性”(rapid elasticity)就是五个基本特性之一。弹性是云计算的基本特性之一,也是云计算的一个最重要的优势和价值之一。亚马逊 AWS 在 2006 年推出的 EC2(Elastic Compute Cloud)就以弹性作为其关键词。类似的,阿里云的云服务器 ECS(Elastic Compute Service),也是以弹性作为其关键词。
在云环境下,根据系统负载自动增加或减少资源的功能特性,被称为弹性伸缩(elastic scaling 或 auto scaling)。静态伸缩与弹性伸缩的对比,如下图所示[26]。
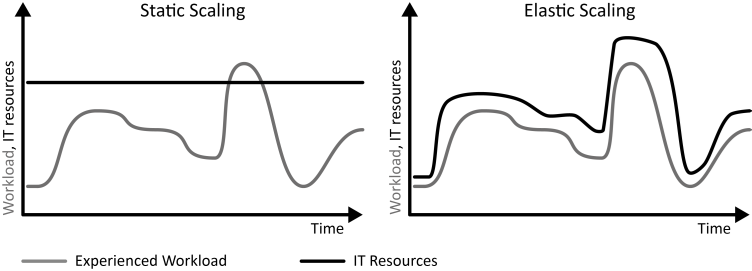
云环境的弹性伸缩的具体方案有,亚马逊 AWS 的“Auto Scaling”、阿里云的弹性伸缩 ESS 、基于 Kubernetes 的容器弹性伸缩等。弹性能力上,云虚拟机可以实现分钟级弹性响应,而以容器技术为基础的云原生技术架构可以实现秒级甚至毫秒级的弹性响应。
维基百科的“弹性伸缩”词条,给出了弹性伸缩的 5 点优势:
- 对于服务运行在自建机房的公司,弹性伸缩通常意味着允许一些服务器在低负载时进入睡眠状态,从而节省电费(以及用于冷却机器的水费和水费)。
- 对于使用在托管在云上的机房的公司而言,自动扩展可能意味着更低的费用,因为大多数云提供商都基于总使用量而不是最大容量进行收费。
- 即使对于不能在任何给定时间减少运行或支付的总计算能力的公司,它们也可以在低流量时降低服务器的负载。
- 弹性伸缩解决方案(例如Amazon Web Services提供的解决方案)还可以用来替换异常状态的实例,从而在一定程度上防止硬件,网络和应用程序故障。
- 在生产工作负载经常变化且不可预测的情况下,弹性伸缩可以提供更长的正常运行时间和更高的可用性。
简单来说,弹性伸缩的主要优势是,节省服务器成本,并且能应对不可预测的突发流量,还有能容忍服务器故障。
2011 年 11 月,Amazon 网站全部都迁移到了 AWS 云服务器上[27]。迁移到 AWS 上最大的动机是能利用 AWS 云服务器的弹性伸缩能力,从而节省成本。如果没有弹性伸缩能力,在淡季时,总体上服务器资源容量的利用率是 61%,无法有效利用的容量是 39%,到购物季的 11 月,无法有效利用的容量高到 76%。引入弹性伸缩技术后,可以按网站的实际流量负载情况,供应恰当的容量,避免资源浪费。Amazon 网站在淡季和购物季时的静态伸缩与弹性伸缩,如下图所示[27:1][28]。



类似的,阿里淘宝、天猫电商系统,为了应对双 11 大促,2015 年开始采用混合云弹性架构,即专有云+公共云,当本地保有云无法支撑时,就快速在公有云上扩容,当流量过去后,再还资源给公有云。2019 年双 11,阿里电商的全部核心应用迁移到公共云,到 2021 年双 11,阿里电商系统实现了 100% 上公共云[29]。
参考资料
数据密集型应用系统设计 DDIA,Martin Kleppmann,2015,豆瓣:第1章 可靠、可扩展与可维护的应用系统 ↩︎ ↩︎
2020-10 Azure AZ-900 Training: Some key cloud concepts https://www.azureguru.org/some-key-cloud-concepts-2/ ↩︎ ↩︎ ↩︎
AWS Well-Architected Framework: Concepts https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concepts.wa-concepts.en.html ↩︎
软件系统架构:使用视点和视角与利益相关者合作,Nick Rozanski & Eoin Woods,第2版2011,豆瓣:第26章 性能和可伸缩性视角 ↩︎
软件架构:架构模式、特征及实践指南,Mark Richards & Neal Ford,2020,豆瓣:第4章 现有的架构特征 ↩︎ ↩︎
2007-10 Gavin Terrill:你真的明白什么是可伸缩性吗? https://www.infoq.cn/article/2007/10/whatisscalability ↩︎
2022-04 CMU SEI: Extensibility https://insights.sei.cmu.edu/library/extensibility/ ↩︎
2010-09 Cary Millsap: Thinking Clearly about Performance https://queue.acm.org/detail.cfm?id=1854041 ↩︎
2015-12 小米马利超:小米抢购限流峰值系统「大秒」架构解密 https://mp.weixin.qq.com/s/enRMYmss6Y5AUCvAMfpHtA ↩︎
2011-07 jianchen:秒杀相关知识以及技术(淘宝秒杀) https://www.iteye.com/blog/jianchen-1113296 ↩︎
2016-03 淘宝许令波:淘宝大秒系统设计详解 https://www.toutiao.com/article/6260281405876470273 ↩︎
2006-11 Randy Shoup, Dan Pritchett: The eBay Architecture (SDForum2006, slides, 37p) https://www.modb.pro/doc/116040 ↩︎
2008-06 Randy Shoup:可伸缩性最佳实践:来自 eBay 的经验 https://www.infoq.cn/article/ebay-scalability-best-practices ↩︎
微服务架构设计模式,Chris Richardson,2018,豆瓣:第1章 逃离单体地狱,1.4.1 扩展立方体和服务,图1-3 扩展立方体 ↩︎
2007-06 SOA done right: the Amazon strategy https://www.zdnet.com/article/soa-done-right-the-amazon-strategy/ ↩︎
2011-05 How the cloud helps Netflix (interview Adrian Cockcroft) http://radar.oreilly.com/2011/05/netflix-cloud.html ↩︎
2014-03 James Lewis & Martin Fowler: Microservices https://martinfowler.com/articles/microservices.html ↩︎ ↩︎
2014-11 Microservices • Martin Fowler • GOTO 2014 https://youtu.be/wgdBVIX9ifA?t=880 ↩︎
2019-08 Static Analysis at Scale: An Instagram Story https://instagram-engineering.com/8f498ab71a0c ↩︎
2013-03 Instagram 5位传奇工程师背后的技术揭秘 https://web.archive.org/web/0/http://www.csdn.net/article/2013-03-28/2814698-The-technologie- behind-Instagram ↩︎
2017-03 Lisa Guo: Scaling Instagram Infrastructure(QCon London 2017, 87p) https://www.infoq.com/presentations/instagram-scale-infrastructure/ ↩︎
2013-08 Reddit: Lessons Learned from Mistakes Made Scaling to 1 Billion Pageviews a Month http://highscalability.com/blog/2013/8/26/reddit-lessons-learned-from-mistakes-made-scaling-to-1-billi.html ↩︎
2016-11 What is the difference between scalability and elasticity? https://stackoverflow.com/a/9610186/689699 ↩︎
2020-03 AZ-900: Cloud Concepts - Scalability and Elasticity https://www.skylinesacademy.com/blog/2020/3/6/az-900-cloud-concepts-scalability-and-elasticity ↩︎
2011-07 2011 AWS Tour Australia, Closing Keynote: How Amazon migrated to AWS, by Jon Jenkins https://www.slideshare.net/AmazonWebServices/2011-aws-tour-australia-closing-keynote-how-amazoncom-migrated-to-aws-by-jon-jenkins ↩︎ ↩︎
2017-03 AWS: Elasticity and Management https://www.slideshare.net/AmazonWebServices/elasticity-and-management ↩︎
2021-11 2021天猫双11:首个100%的云上双11,体验如丝般顺滑 https://www.sohu.com/a/500431383_114930 ↩︎